This project was a complete, ground-up reimagining of our core FinTech SaaS platform. It included a new user experience, new API, new backend, and new infrastructure. Normally, one would prefer to reuse or evolve a codebase rather than start fresh, but years of neglect and shifting markets dictated we bring a fresh approach to the product, UX, and technology.
Oh, and by the way, we implemented more capability in less than 10% of the lines of code as the previous product. That’s the power of cloud computing!
The product still serves the same general market: risk compliance, specifically AML/KYC and sanction screening. However, we knew that our existing product’s feature set and go-to-market strategy had not kept pace with our evolving customer needs and our competition.
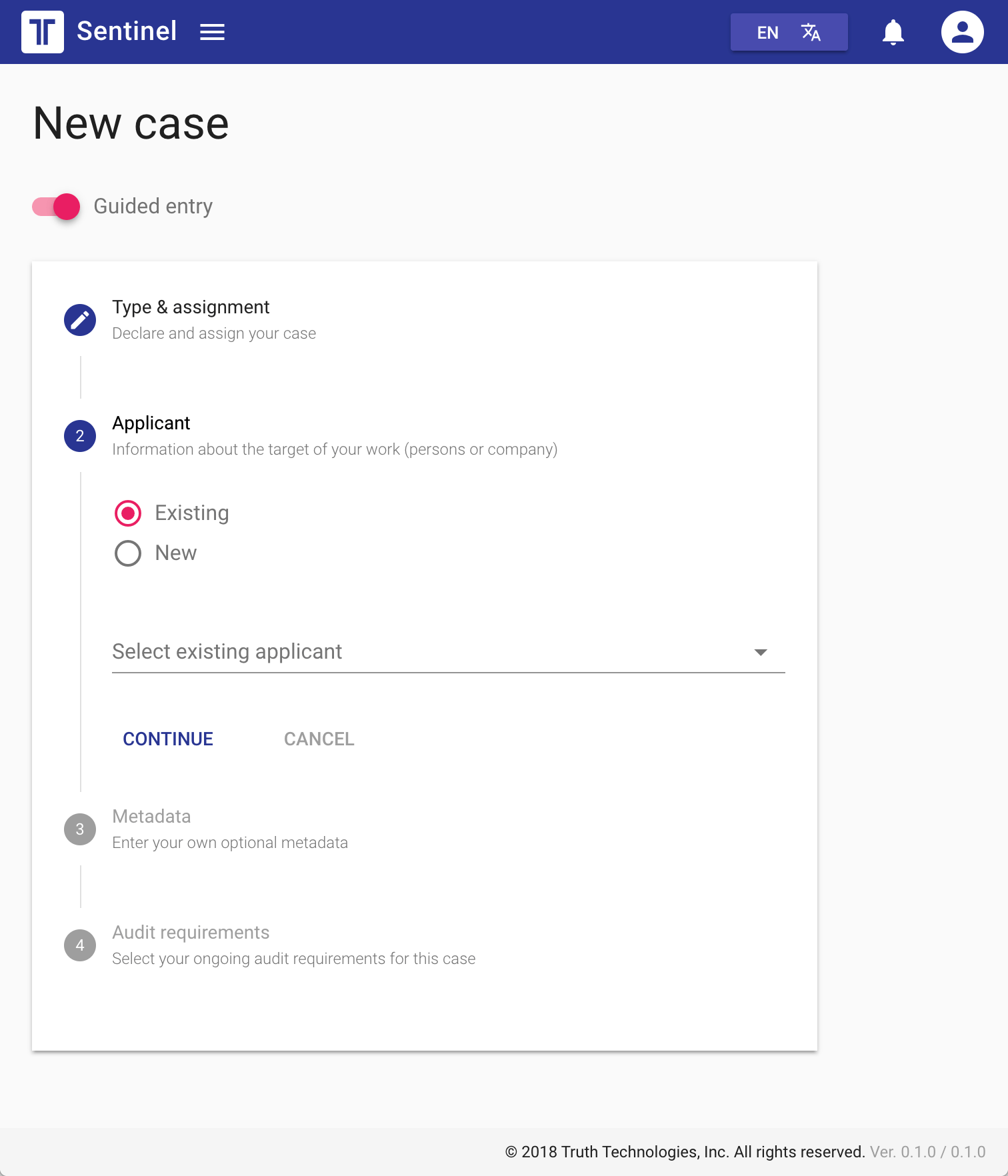
So, we started by reducing the product to its core functions & features, the primary workflow, and the basics of what customers generally need to accomplish day-to-day. We’ve got to handle the basics if we’re going to really solve the problems of front-line folks.
Next, we laid out a critical path for a minimum viable product (MVP) so we could rapidly test out a new experience on existing customers, and potentially capture new customers looking for a streamlined solution of core features. How much better can we solve these problems before we add complexity.
From there, we got to work on other product development, including a new pricing model. I can’t understate enough how much pricing models need to align with your features and vice-versa.
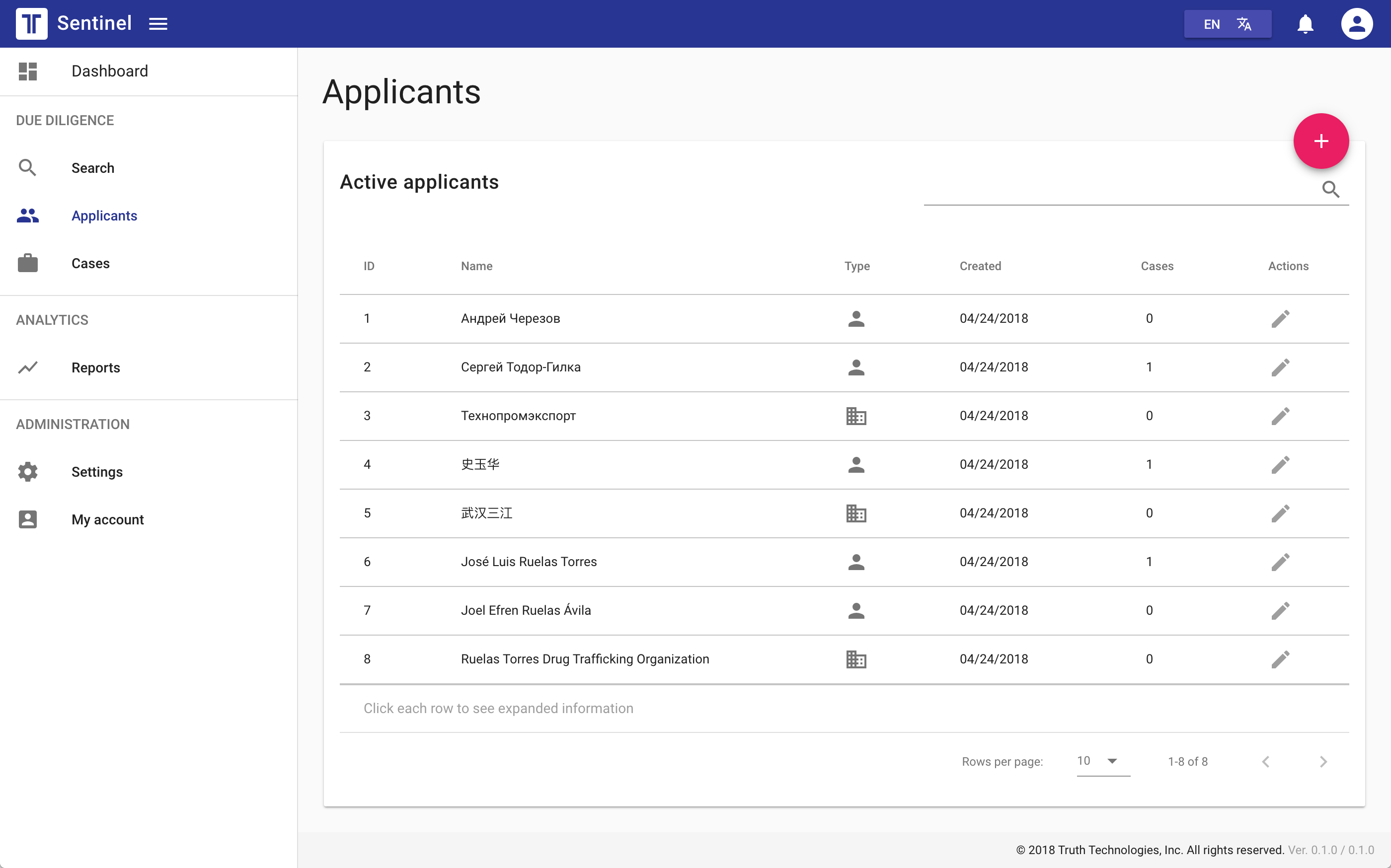
User Experience
Our core driving mantra was simplicity, and there are several reasons for making that the focus.
Simple user experiences are generally easier to learn.
Simple user interfaces are generally easier to maintain.
Adding features typically adds complexity.
Our audience typically lags behind newer technologies.
… and other reasons.
So, I opted for a simple & consistent layout and a responsive design that works well on multiple devices. We generally followed Material Design as a conscious choice. This design language is quite familiar to many people by now and our needs didn’t warrant offering anything disruptive in this area.
If you’re curious, prototyping and graphics were done using Sketch.
Algorithm & Technical Advances
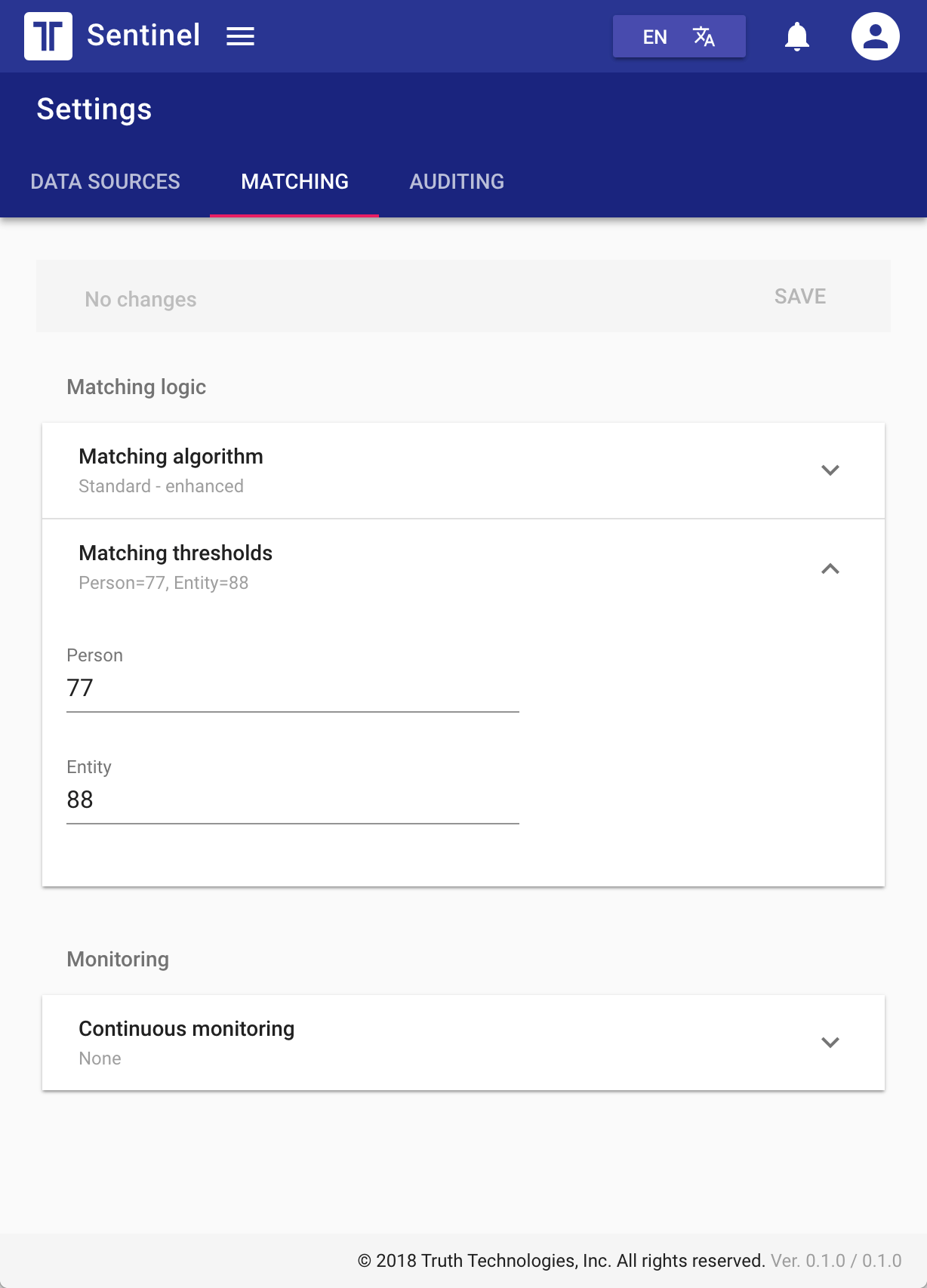
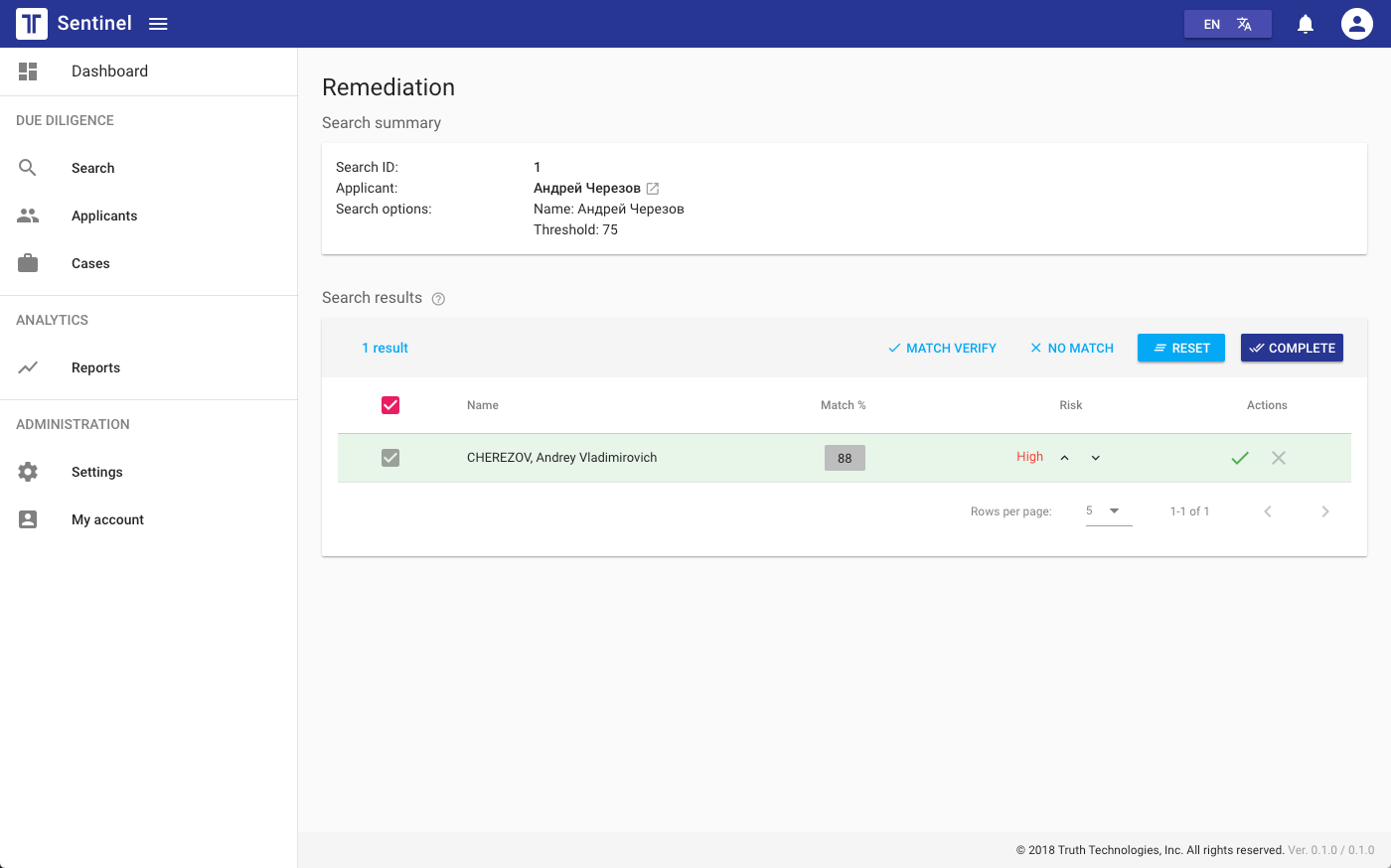
The new application offers significant performance improvements over the prior version, most specifically regarding the name matching algorithm. This algorithm is a core part of the application, so improving on it was a big win.
My contribution was to architect the implementation, build the queries, and test & tune the algorithm.
Testing was conducted against 3,000 individual test cases, comprised of real-world examples of misspellings, transpositions (letters and first/last names), missing characters, and other assorted conditions. These tests came from several of our customers and were used in algorithm tuning by compliance auditors. In other words, these are conditions you may encounter in the wild.
New Product vs Old Product Comparative Results
Our new algorithm performed better in all categories, and so we’ll look at three of the more important categories relevant to end users.
Testing parameters
Threshold: 75 (a typical “score” value that approximates closeness of underlying data to user input)
Max results/query: 10 (the maximum number of results returned as part of a single match, sorted by score)
Data Source: SDN/CSL (OFAC’s Specially Designated Nationals and Consolidated Sanctions List are the baseline)
First match hit rate
The first match hit rate represents the percentage of occurrences where the top match in any result set is the true match. Obviously, higher is better. We were very pleased with the improvement, though not surprised by the poor performance of the old product. Often times, our customers complained that the true match was buried in the list of results. No more!!!
Benefits: Higher confidence, faster workflow
Algorithm first match hit rate
False positive rate (inclusive, all results)
The false positive rate represents the percentage of occurrences where the algorithm returned records in addition to the true match. For example, if the algorithm returned four total records, then we would count this as returning one or more false positives. Overall, you want a low false positive rate. Ideally, you’d want to algorithm to return one and only one resulting match, and that match to be the true match.
As you can see, our new product offered a vast improvement over the old product. While one could argue that one additional false positive alongside your true match isn’t a big deal, it’s actually doubling your work. It gets even worse when you add more and more false positives. The next metric provides more context.
Benefits: Higher confidence, less noise, faster workflow
False positive volume
The false positive volume represents the average number of records returned in a result set. Ideally, you’d want one and only one record returned and have confidence it’s always the true match. Our new product nearly matches that goal with just over one record in each result set, compared with nearly four in the old product.
What we’ve basically done is cut the time a user reviews records by roughly 70%!
Benefits: Less noise, faster workflow
Technology
The application stack is pretty exciting as it’s a collection of pretty hot topics. It’s also a bit pervasive, so community support and maintenance should be quite good for a while at least.
Backend: Node.js, PostgreSQL, Google Cloud Platform (GCP)
API or middle tier: Node.js, Elasticsearch, Koa.js
Frontend: JavaScript, Vue.js, Vuetify